The last time I wrote on NoSQL
databases in February 2011, the technology was already booming. Today, these
databases have changed the way developers think about building their
applications; making them look beyond RDBMS back-ends to even handle data on a
massive scale. Some very unique data models that were earlier impossible with
conventional databases are now possible with NoSQL databases and clustering.
One such NoSQL database is Cassandra, which was donated to Apache by Facebook
in 2008.

Apache
Cassandra the Crash-Proof Nosql Database
Cassandra’s most enticing and central
feature is that it is decentralized and has no single point of failure. It is a
column-oriented database, which was initially inspired and based on Amazon's
Dynamo for its distributed design. The decentralized design makes it immune to
almost any type of outage that affects a part of the cluster, while the column
family-based design allows for richer, more complex data models that resemble
Google's BigTable. This has allowed it to develop a good amalgamation of features
from both Dynamo and BigTable, while evolving into a top-notch choice for
production environments in various organizations, including the place where it
was created – Facebook.
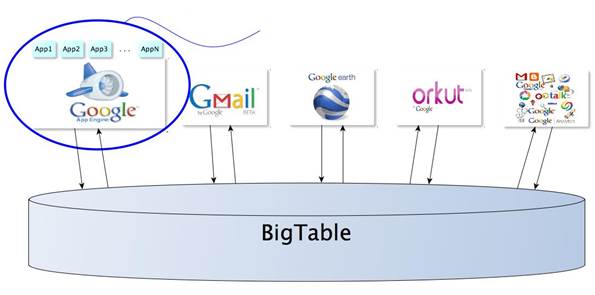
Cassandra
has allowed it to develop a good amalgamation of features from both Dynamo and
BigTable
Another concept that is important to
Cassandra is eventual consistency, which is increasingly being looked at in the
context of Brewer's CAP theorem, which I had discussed in the earlier article.
Eventual consistency, as its name suggests, offers huge performance benefits by
assuming that consistency does not need to be guaranteed immediately at all
points in the database, and that it can be relaxed to some extent. This is
achieved by what is known as a tunable consistency model, which uses the
consistency level setting to be specified with each operation, so that they are
deemed to be successful even if data has not been written to all replicas.
Architecture
Cassandra uses so many components to build
upon its complex architectural theory that it is really difficult to go through
all the bits and pieces without missing anything. The terminologies discussed
here are those that provide an insight into the inner workings of this
database. Cassandra's architecture is built more towards avoiding a single
point of failure in the cluster, so as to have unhindered access to the maximum
amount of data in case any part of the cluster fails. It uses technologies that
resemble peer-to-peer networking to achieve a failure-proof data distribution
model. Hence, no single node in a Cassandra cluster can be termed as a master
of others, and coordination among the nodes is achieved with the help of the
Gossip failure detection protocol, which is used to determine the availability
of a node in the cluster.
Gossip is managed with the help of the
Gossiper present on each node, which keeps on initiating ‘Gossip’
communications periodically with random nodes to check their availability. As a
result, each node performs similar functions to others, and there are no
designated roles for a particular function.

Gossip
is managed with the help of the Gossiper present on each node, which keeps on
initiating ‘Gossip’ communications periodically with random nodes to check
their availability
Each node in Cassandra is part of a ring,
which determines the way in which the topology of a Cassandra cluster is
represented. Each node in the cluster is assigned a token, and a part of the
data for which it is responsible. The data to be assigned to each node is
determined by the Partitioner, which allows the row keys to be sorted according
to the partitioning strategy chosen. The default strategy is random
partitioning, which works on the basis of consistent hashing to distribute row
keys. Another partitioning strategy available is the use of Byte-Ordered
Partitioner, which orders row keys according to their raw bytes. AntiEntropy is
then used to synchronize the replicas of the data to the newest version by
periodically comparing the checksums. Merkle trees are used in Cassandra to
implement AntiEntropy, just like for Dynamo, but in a slightly different way.
For more details, you could read the respective documentation.
Reads and writes
When a node receives a read request from
the client, it first determines the consistency level specified in it, on the
basis of which it determines the number of replicas that need to be contacted.
When each replica responds with the requested data, it is then compared to
determine the most recent version to be reported back. If the consistency level
specified is a weaker one, then the latest revision is immediately reported
back, and then out-of-date replicas are updated. If it is one of the stronger
consistency levels, then first a read repair operation is performed, after
which the data is reported back.
In case of a write operation, the
consistency level is again used to determine the amount of nodes required to
respond with an acknowledgement of success, before the whole operation is
deemed to be successful. If the nodes required for consistency are not
available, then mechanisms like ‘hinted handoff’ are used to ensure consistency
whenever the node comes back online. The complete flow for a write operation
involves components like the commit logs, Memtables, SSTables, etc. The commit
logs are the first failover protection mechanism, where the operation is
written so that the written data can be recovered in case of a failure. The
memtables then act as an in-memory database, where all the data is updated
until it is flushed to disk in the form of SSTables. Compaction is then
periodically performed to assimilate data, so that it can be merged into a
single file.