The data model
The data model for Cassandra is
column-family-based, which resembles the design for relational databases using
tables. In this case, however, the data model works in a fundamentally different
manner to fixed-size columns.
In Cassandra, the database schema is not
required to be fixed before the application is used – and it can actually be
updated on the fly without any problems on the server. In most cases, the
client can arbitrarily determine the number of columns and metadata it wants to
store in a particular column family. This results in much more flexibility for
the application and in rows that vary in size and in the number of columns.
Keyspaces are used to define the namespace
for each application’s column families. Hence, these can be defined on a
per-application basis, or according to any other schema design that is
required. Column families can be of two types – static and dynamic. The static
column family allows predefined columns in which a value may or may not be
stored. Dynamic column families, on the other hand, allow the application to
define columns whenever they are needed according to their usage. While
specifying a column, its name, value and timestamp are needed. So basically, a
column is the most basic unit in which a piece of information can be stored.
Cassandra also supports structures like super columns and composite columns,
which allow for further nesting.

Cassandra
is based on google big table data model. It is called “Column DB”. It is
totally different from traditional RDBMS.
Almost all RDBMS' require you to specify a
data type for each column. Though Cassandra does not have any such strong
requirements, it allows specification of comparators and validators, which act
like a data type for the column name and the column’s value, respectively.
Except for counters, almost all data types like integer, float, double, text,
Boolean, etc., can be used for comparators and validators.
Installation and configuration
The binary for installing Cassandra can be
found at cassandra.apache.org/download. This is available in the form of a
compressed file, which can be easily extracted on any OS. Before installation,
ensure that Java 1.6 is available on the system, and that the JAVA_HOME
environment variable has been set. Once the extracted files have been placed in
the desired directory, the following commands can be used (on Linux) to set up
the environment:
sudo mkdir -p
/var/log/cassandra
sudo chown -R
`whoami` /var/log/cassandra
sudo mkdir -p
/var/lib/cassandra
sudo chown -R
`whoami` /var/lib/Cassandra
For Debian-based Linux distributions like
Ubuntu, you can directly install it from the Apache repositories, for which you
can add the following lines to ‘Software Sources’:
Deb
http://www.apache.org/dist/cassandra/debian 12 x main
Deb-src
http://www.apache.org/dist/cassandra/debian 12 x main
Additionally,
there are two GPG keys to be added, as follows:
gpg
--keyserver pgp.mit.edu --recv-keys F758CE318D77295D
gpg --export
--armor F758CE318D77295D | sudo apt-key add -
gpg
--keyserver pgp.mit.edu --recv-keys 2B5C1B00
gpg --export
--armor 2B5C1B00 | sudo apt-key add –
Cassandra can now be installed with the
simple sudo apt-get install Cassandra. The most basic configuration starts by
confirming that all the files and folders have proper permissions. The file
conf/cassandra.yaml lists all the defaults for other important locations.
Cassandra can now be started by running the following command, which starts the
server in the foreground and logs all the output on the terminal:
bin/cassandra
–f
To run it in the background as a daemon,
use the same command without the -f option. To check if it is running properly,
try and access the command-line interface by running the bin/Cassandra-cli command.
If there are still no errors and you are greeted with a prompt, then your
installation has been successful. You can also try and run the CQL prompt
(bin/cqlsh). For detailed instructions on how to set up a cluster, access the
official documentation, although it does not cover much beyond some basic
configuration. In short, you need to install Cassandra on each node similarly,
and specify the earlier node as the seed. An IP interface for Gossip and Thrift
are also required to be set up beforehand.
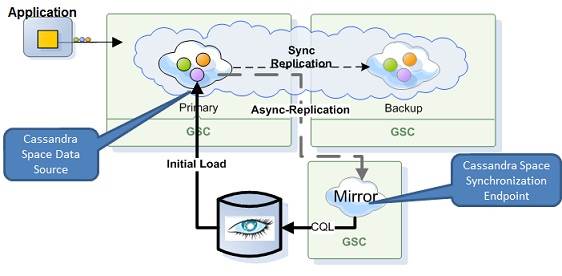
For
further details about the persistency APIs used see Space Persistency.
Connecting to Cassandra and using client
libraries
Cassandra provides several client APIs to
access the database directly from your development environment and a lot of
client libraries for many languages like Python, Java, Ruby, Perl, PHP, .NET,
C++, Erlang, etc. Even if the required library isn't available, you can use the
Thrift interface directly. The Thrift framework supports almost every available
language, and allows for cross-platform development by writing simple Thrift
files that define the interface between a client and server application.
Cassandra also supports a new interface
known as CQL (Cassandra Query Language), which is an SQL clone. It
syntactically resembles SQL, besides being more suitable for this data model by
allowing for column families and skipping on features like joins, which are not
required in the context of a NoSQL data model. CQL is basically a wrapper that
provides abstraction to the internal Thrift API, and makes the developer's job
much easier by simplifying things. A CQL sample used to create a keyspace looks
like what’s shown below:
CREATE
KEYSPACE Test
WITH
replication = {‘class’: ‘SimpleStrategy’, ‘replication_factor’: 3};
These commands can be run at the cqlsh
prompt or using drivers available for languages like Java, Python, PHP, Ruby,
etc. (These drivers require Thrift to be installed before use.)
The best part about using Cassandra is that
it doesn't miss out on the analytical power provided by Hadoop's MapReduce.
Setting this up is pretty easy, as Hadoop can directly be overlaid on top of a
Cassandra cluster by having Task Trackers that are local to the Cassandra
Analytics cluster, while Hadoop's Name Node and Job Tracker remain separate from
the cluster on a different machine. Cassandra provides very good integration to
facilitate working with Hadoop MapReduce jobs, and to provide easier access to
data stored in Cassandra so that it can be used with other higher-level tools
like Pig and Hive.
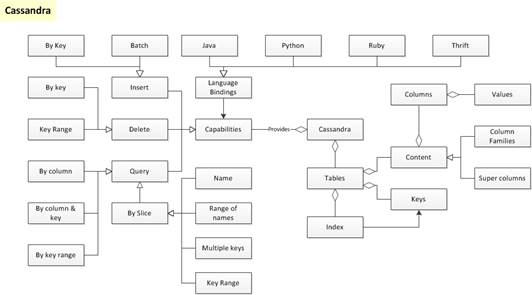
Connecting
to Cassandra and using client libraries
So, we have covered enough about Cassandra
for a basic understanding of the important terminology. I have, however,
skipped a lot of details that would have been beyond the scope of this article,
including the various methods by which we can work with Cassandra, and other
theoretical portions like replication strategies, network topology management,
security, maintenance and performance tuning.