Trying to read ordinary text can be fraught
when it’s displayed as gibberish
Text Was, Along with numbers, the first human-readable data type to be widely used
in computers and has long been showing signs of that age. The most persistent
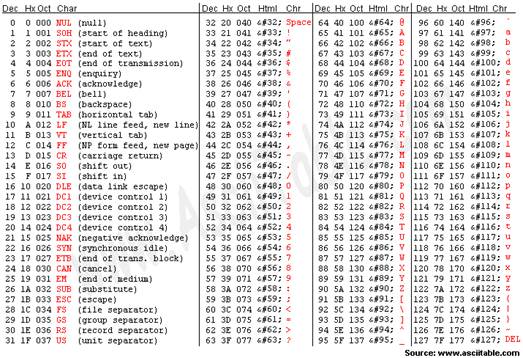
standard for encoding text, adopted as the American Standard Code for
Information Interchange (ASCII) basic level, will celebrate its half-century
next year. It uses only 7 bits to provide 128 different characters, including
the complete upper- and lower-case Roman alphabet and a modest collection of
digits, punctuation marks and control characters. It supports plain English
text quite well, but ignores the vast majority of other languages.

If
you don’t encode your text properly, the resulting file could be as hard to
decipher as the Rosetta Stone
By contrast, the current Unicode 6.1
standard (sometimes referred to in its parallel ISO/IEC 10646 Universal
Character Set form) used for all text on OS, iOS and most other modern computer
systems uses 8, 16 or sometimes 32 bits to represent well over 110,000
characters, for 100 different script systems, encompassing pretty well every
living language and most dead ones, too. If only everyone and all software
could stick to using that new standard, life with text would be much more
straightforward.
It still wouldn’t be entirely simple,
though – for example, some software may automatically render certain character
sequences differently; separate letters ‘f’ and ‘i’ may be encoded as the
single Unicode character ‘Latin Small Ligature fi’, which will be preferable
for typesetting. However, if you search document content for the word ‘confirm’
and don’t include ‘con[Latin Small Ligature fi]rm’ as an alternative in your
search, then you won’t get all possible hits.
Life with text becomes even more complex
when you have to work with languages that can’t be expressed within the
small col-lection of Roman characters offered by ASCII alone. Those with
relatively few characters continued to use 7 or 8 bits, effectively conflicting
with ASCII: the workaround used to accommodate these is widely known as the
‘code page’. For example Cyrillic text might be set using KOI8, one of several
different code pages used for that purpose. The snag is that unless you guess
the correct code page to use, the content will be garbage when rendered using,
say, a code page for MIK – a phenomenon known as ‘mojibake’ because of its
frequency when working in Japanese. To add to the inevitable confusion code
pages used on Macs generally differ from those on PCs.
ACSII
The biggest problems come when trying to
represent languages with far more characters than can be accommodated in a mere
8 bits, particularly Chinese, Japanese and Korean. More complex workarounds
have been developed for these, usually involving simplified character sets,
such as Hangul jamo for Korean, and multi-byte characters that differ from Unicode.
Even if you know which language you’re dealing with, there will still be
several very different possibilities as to how it has been encoded. And Unicode
has stopped short of trying to support all written characters in each of the
three major languages, opting instead for a unified and simplified system known
as Unihan.
At the moment, there’s a huge legacy of
text encoded using non-ASCII code pages, major sources of text content (HTML
and PDF in particular) that still don’t generally encode it using Unicode,
fonts that use older code page-based encodings rather than Unicode, and plenty
of pre-Unicode computer systems and software that are still busily generating
content using a wide range of text encoding schemes. The Tower of Babel lives
on.
HTML and PDF
issues shouldn’t occur, but it’s only relatively recently that they’ve started
to embrace Unicode, and even now haven’t generally enforced it as a
requirement. In any case, the vast number of web pages and PDF documents that
already use non-Unicode text encoding schemes is going to take a generation or
more to fade away. Websites must be properly configured to send HTML headers
assigning the coding scheme explicitly, or provide metatags as a substitute,
and should now be cast in an appropriate Unicode form such as UTF-8 even
if they only contain content that can be encoded wholly within the original
ASCII set.
PDF is a
more complex problem, given that most documents being written to PDF files
still adhere to older versions of the PDF standard and may not cross encoding
schemes intact. Wherever possible, use the most recent PDF version that readers
will be able to support, embed the necessary fonts and opt for Unicode
encoding, particularly if the document will be read on systems whose primary
character set won’t be limited to ASCII. For archival work, compliance with
PDF/A-1a or /A-2u ensures that every character must have a Unicode equivalent.
Those standards seem to be gradually over-coming Adobe’s long-standing
reluctance to accept universal accessibility of content within PDF documents.
When you try to access content encoded
using older, non-ASCII schemes, you can easily end up with mojibake. For
example, you might be able to view a document correctly in a PDF viewer or when
rendered by a browser, but when copied out or saved as text or a text-based
format such as RTF, it loses its encoding. Although this should happen less
often now that OS X encodes all text using Unicode, it remains a problem with
many older documents.
Even in Roman text it isn’t uncommon for
characters beyond the original, 7-bit ASCII set to become scrambled – this is
most frequent with smart quotation marks, dashes and currency symbols. In other
cases, the main body of text is correctly converted, but special characters
rendered in a custom font, perhaps to represent archaic script, may drop out as
rectangular place markers.