You Then Need to determine what’s causing the problem. If the text can be viewed
when rendered with the correct code page or other encoding scheme, then it’s
best to identify that (almost invariably by trial and error), and having
engaged the correct scheme convert the content to modern Unicode text; for most
languages, that’s likely to be 8-bit Unicode, UTF-8.
If the encoding is idiosyncratic and
doesn’t generally conform to a recognized scheme, you may end up having to remap
characters using search and replace, which requires a specialist text
editor or a tool such as Text Soap.
Another possibility that you shouldn’t
overlook is that the characters are encoded correctly and accessibly, but your
system lacks an appropriate font in which to render them faithfully. The
latter can be avoided if you retain the complete set of fonts installed with OS
X, together with the near-universal cover provided by freeware DejaVu (from
dejavu-fonts.org/wiki/Main_Page).
Many Eastern Bloc countries used custom
fonts based on idiosyncratic 7- or 8-bit encoding schemes. If you don’t use
those specific fonts to render respective documents, the characters shown will
be scrambled to a greater or lesser degree.
Sometimes fonts produced by the same
foundry used slightly different encodings, and authors mixed those in single
documents. Making sense of the result can take so much effort that it’s likely
to be quicker and cheaper to perform OCR on scanned images – this may be the
last resort before you have to give up hope and get the text typed in afresh.
Cleaning up Mojibake and messy text
Many Apps Can read or write text files using a selection of common code pages.
However, when working with Asian languages in particular, the choice available
often doesn’t include even the most popular encoding schemes such as JIS and
Shift-JIS (for Japanese). This is also unlikely to be a good way of identifying
which code page or encoding is used in a file that appears in mojibake. For
those, you need Text Encoding Converter, as this displays the start of the file
using five different methods, four of which you can choose quickly from its
near-comprehensive range. You then switch between methods until what you see
makes sense. Text Soap is the ultimate collection of cleaning and conversion
tools, with well over 100 filters on offer, from a wide-ranging ‘Scrub’ that
tackles most common issues, to many acting on single characters. They cater for
plain text, markdown, HTML and XML property lists, and issues that arise when
converting between each.
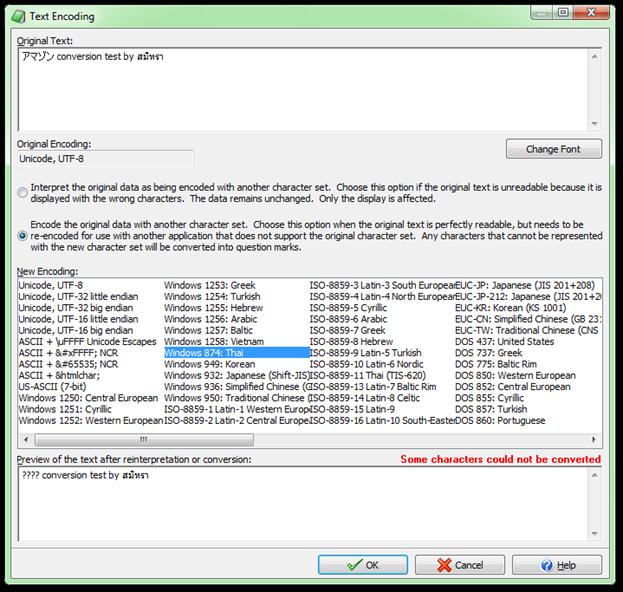
You
need Text Encoding Converter, as this displays the start of the file using five
different methods
You can also construct your own custom
filters using those supplied and generic tools such as search and replace. For
instance, if you’re struggling to convert mojibake from an Eastern European
language, you can replace each duff ASCII character with the correct Unicode
one, using a bulk find and replace, which is also a good way to split ligatures
such as ‘ffi’ back to their constituents. The use of regular expressions is
both supported and assisted. Filters can be applied to whole documents, batches
and text selected in its built-in editor, making it straightforward to deal
with mixed-language files. The only significant issue in use is that undoing a
filter can take forever and consume large amounts of disk space, so save before
applying a filter and be prepared to revert if the filter isn’t as successful
as you had hoped.
True text editing
Many Popular Apps provide limited facilities for working with text content, but it
usually repays to use a dedicated text editor, no matter how unfashion-able
that may seem. Apple’s free TextEdit does work with plain text, but has a nasty
habit of dropping back into RTF at the least excuse, and lacks power features
that will save you time and error.
BBEdit is still king of Mac text editors,
with its free counterpart Text Wrangler a fair substitute for the occasional
user. In addition to a wealth of features aimed at those who code HTML in the
raw, and for authoring in a range of different programming languages, it’s an
ideal platform for manipulating text content and keeping it in plain Unicode
formats. Search and replace can be operated in a native fashion that’s very
accessible, or can be switched to handle regular expressions using Unix grape.
If you’re not familiar with this, BBEdit’s manual provides a sound tutorial and
reference.
Multi-file search extends the same two
methods over all files in designated folders, returning a special window that
might have come from a specialist concordance tool, enabling you to view every
hit in context in its source file. Another powerful command lets you compare
two files, showing a third window enumerating the differences between them,
letting you step through the originals one difference at a time.
BBEdit has several good tools for cleaning
up text in different ways, can be scripted extensively using AppleScript and
lets you construct your own filters, known as ‘text factories’, which can also
be applied to a batch of files. One current limitation is that custom filters
or factories can’t easily be applied to selections within a file, although the
documentation states that they can. Hopefully, this bug will be fixed shortly.