Over the next few columns, we will
take a look at data storage systems, and how they are evolving to cater to the
data-centric computing world.
Last month, we featured a special edition
of ‘CodeSport’, which discussed the evolution of programming languages over the
past 10 years, and how they are likely to evolve over the coming 10 years. The
article went on to hazard a guess that the ‘Big Data’ explosion would shift the
momentum to languages that make data processing simple and efficient, and make
programs ‘data centric’ instead of the ‘code-centric’ perspective. Many of our
readers had responded with their own views on how they see computing paradigms
evolving over the coming 10 years. Thanks a lot to all our readers for their
feedback and thoughts.
CodeSport
- Given The Importance Of Data Storage In A ‘Big Data’ World
One of our readers, Ravi Krishnan, sent me
a pertinent comment, which I want to share: “Thank you for your article on the
evolution of programming languages. Indeed, there is a heavy momentum towards
processing huge amounts of data using commodity hardware and software. While
the basic concepts and algorithms of computer science would continue to hold
sway, the sheer scale of the data explosion would require programmers to
understand and apply algorithms where data does not fit in main memory. Hence
programmers need to start worrying about data latency of secondary storage such
as flash SSD/disk storage systems. In a way, the shift towards data-centric
computing means more intelligent storage systems, and a need for programmers to
understand about state-of-the-art storage systems, where big data is stored,
processed and preserved. While this is not a traditional topic covered in
‘CodeSport’, given the importance of data storage in a ‘Big Data’ world, it
would be great if ‘CodeSport’ does a deep-dive into state-of-the-art storage
systems in a future column”.
It was a timely reminder for me. While I
have discussed various ‘Big Data’ computing paradigms in some of our past
columns, I have not covered storage systems at all. So over the next few
columns, I am going to discuss storage systems, and how they have evolved over
years to cater to the ‘Big Data’ explosion. I will take readers through some of
the challenging problems as well as the state-of-the-art research directions in
this space.
A storage systems primer
Let us start our journey into storage by
understanding some of the basic concepts and terminology. In the traditional
view of storage, we all know about the triumvirate of the CPU, memory and disk,
where the hard disk (also known as secondary storage) is part of, or directly
attached to your computer, and acts as the permanent storage. From now onwards,
when I use the term ‘storage’, I actually imply the traditional secondary
storage, which acts as the backup to the main memory (which is the primary
storage). These include hard disk drives, flash/SSD storage, tape drives, etc.
Traditional HDDs are accessed using a
variety of protocols such as SCSI, ATA, SATA and SAS. SCSI stands for Small
Computer System Interface and is a parallel peripheral interface standard
widely used in personal computers for attaching printers and hard-disks. ATA is
another interface used for attaching disks also known as IDE, wherein the
controller is integrated into the disk drive itself. ATA is also a parallel
interface like SCSI and both have their equivalent serial interfaces namely,
Serial SCSI (abbreviated as SAS) and Serial ATA (abbreviated as SATA) which
allow a serial stream of data to be transmitted between the PC and the disk
drive.
Note, however, that in the traditional view
of storage, it is part of the compute server, since it is directly attached to
the server and is accessed through it. It is not an independent addressable
entity, and is not shared across multiple computers. Typically, this is known
as ‘Direct Attached Storage’ (DAS). Access to the data in secondary storage is
through the server to which it is attached; hence, if the server is down due to
some failure, the data becomes inaccessible. Also, as data storage requirements
increase, we need to have greater storage capacity. We produce 2.5 quintillion
bytes of information every day, out of the Web searches we do, the online
purchases we make, the mobile calls we make, and the social network presence we
have (a quintillion is 1000 x 1000 x 1000 times a billion). Given the volume of
Big Data that gets produced, the storage requirements go on increasing
exponentially. However, in case of Direct Attached Storage, the number of I/O
cards (for example, SCSI cards) that can be connected to a computer is limited.
Also, the maximum length of a SCSI cable is 25 M. Given these restrictions, the
amount of storage that can be realized using the conventional directly attached
storage is limited. Also note that DAS results in uneven storage utilization.
If one of the servers has used up all its disk storage and needs further
storage, it cannot use any free storage available in the other servers. This is
shown in Figure 1, where disks on Server 2 are full, whereas there is excess
disk capacity available on Servers 1 and 3. However, it is not possible for
Server 2 to use them.
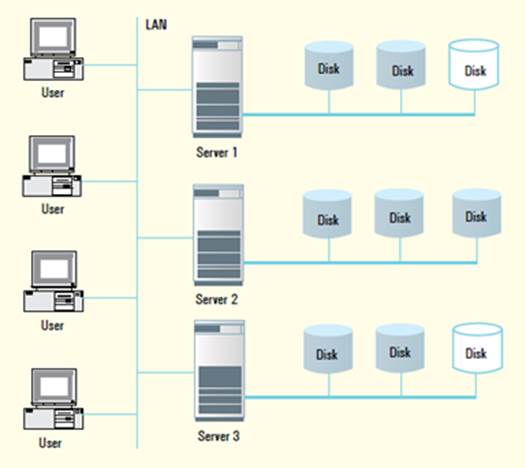
Figure
1: Disks on Server 2 are full
As opposed to the traditional server
centric paradigm we have seen above, in a storage-centric view, storage exists
as an independent entity, apart from the computer servers. Storage can be
addressed independently, from multiple servers. A simple form of a storage
network is shown in Figure 2, where we can visualize the SCSI cables of the
computers having been replaced with connections to the network storage. Though
the storage is an independent entity on a network, to the operating system
running on the compute server, it appears as if locally attached to the compute
server.

Figure
2: Storage network
Two popular forms of storage-centric
architectures are Network Attached Storage (NAS) and Storage Area Network
(SAN). The latter (SAN) allows storage entities to exist in a network, which
can be accessed from compute servers using either special protocols such as
Fibre-Channel or standard TCP/IP protocols such as iSCSI (internet SCSI). SANs
provide block-level access to storage, just like traditional locally attached
storage. In contrast, in the case of Network Attached Storage or NAS, a
dedicated storage computer exists as an entity on the network, and is
accessible from multiple compute servers concurrently. Unlike a SAN, a NAS
provides file-level storage semantics to multiple compute servers, appearing as
a file server to the operating system running on the compute server.
Internally, the NAS file server would access the physical storage at block
level to access the actual data, while this is transparent to the OS on the
compute server, which is exposed only to file-level operations on the NAS
server.
Hybrids of SAN and NAS also exist. Since
there is no file system concept for SANs, various file protection and
access-control mechanisms need to be taken care of in the OS running on the
compute server. In case of NAS, file protections and access control can be
enforced at the NAS server. The next concept we need to understand in the
storage domain is Scale-up Storage vs. Scale-out Storage, which we will discuss
next month.
Remembering Aaron Swartz
It has been almost two months since the
death of Aaron Swartz. Most of us would have read about the enormous outpouring
of grief caused by this tragic loss. Aaron Swartz was a programmer first and
foremost, and the reason I wanted to mention him in our column was not just
because he was a well-known activist who fought for the freedom of information
on the Internet, but because he is a sterling example of what differentiates a
great programmer from the run of the mill. He had an enormous enthusiasm for
building software that solves challenging problems. He was involved in the
development of the RSS format, wrote the Web.py framework, and was a technical
architect of reddit.com, just to mention a few examples of his work. He had a
great passion for expanding and sharing his knowledge with all developers. Rest
in peace, Aaron.
My ‘must-read book’ for this month
This month’s must-read book suggestion
comes from one of our readers, Aruna Rajan. She recommends the book
‘Introduction to Information Retrieval’ by Christopher D. Manning, Prabhakar
Raghavan and Heinrich Schütze. This book focuses on various information
retrieval techniques, including the most popular one of Web search engines. The
book is available online at http://nlp.stanford.edu/IR-book/html/htmledition/irbook.html.
Thank you, Aruna, for your suggestion. If you have a favorite programming
book/article that you think is a must-read for every programmer, please do send
me a note with the book’s name, and a short write-up on why you think it is
useful, so I can mention it in the column. This would help many readers who
want to improve their coding skills. If you have any favorite programming
puzzles that you would like to discuss on this forum, please send them to me,
along with your solutions and feedback, at sandyasm_AT_yahoo_DOT_com. Till we
meet again next month, happy programming and here’s wishing you the very best!