The paradigm shift to Web 2.0 has led
to the enormous popularity of social networking, blogs, articles, and wikis,
resulting in the demand for a huge knowledge base across enterprises.
We have two kinds of data:
1. Structured data, which includes a pre-defined data model that fits
into relational tables, e.g., databases, XML files, and enterprise systems such
as CRM and ERP.
2. Unstructured data, which does not have a predefined data model, and
does not fit into relational models; e.g., RSS feeds, audio files, video files,
word documents, emails, and spreadsheets.
‘Not only SQL’ or NoSQL is a type of
database management system that is not centered on the SQLbased relational
database model. It is extremely effective when working with a huge volume of
structured or unstructured data. NoSQL databases do not use SQL for data
manipulation operations.

A
look at open source Nosql databases and cloud computing
SQL, NoSQL and Cloud Computing
The focus of traditional databases is
mainly on consistency, but being relational is not necessary for some specific
use cases, and can add avoidable overhead. The use of NoSQL databases opens up
the scope for enormous scalability, the ability to grow the capacity of your
database on demand, low latency, and a relatively easier programming model –
which SQL databases do not provide in a cost-effective manner.
In traditional SQL databases, data is
normalized so that it can provide effective results, and prevent isolated
records and duplicate data. Normalizing data requires multiple tables, which
requires multiple join statements, thus requiring more keys and indexes. A
primary disadvantage of SQL databases is the high abstraction level. To execute
a single statement, SQL often requires the data to be processed multiple times,
which takes time, and requires high performance, e.g., multiple queries are
executed when there is a join operation. In addition, RDBMSs might not scale
out easily – but the new breed of NoSQL databases are designed to expand
transparently, and are designed with low-cost commodity hardware in mind.
In SQL databases, there is always a schema
involved. Requirements may change, and the database has to be modified to
support the new requirements. For example, the application may need two extra
fields to store data; with SQL databases, this may take some time and thinking,
while in case of NoSQL, it can be done easily, allowing the database to adopt
new business requirements. However, SQL databases do have the advantage of
better support for Business Intelligence.
The NoSQL world is one without relations,
with pure scalability and no joins. NoSQL databases manage data that is not
rigorously relational and tabular, so do not use SQL for data manipulation. NoSQL
databases are typically non-relational, horizontally scalable, open source, and
distributed. A key advantage of NoSQL over SQL databases is its ability to
scale an application to new levels. NoSQL databases characteristically
highlight horizontal scalability by partitioning and leveraging the elastic
provisioning capabilities of the cloud. The NoSQL data services are based on
scalable architectures and built for the cloud environment. They provide
freedom to select a data model as per needs and use familiar tools.
With NoSQL databases, data replication can
be done more easily than with SQL databases. As NoSQL databases are built
without relations, data need not be on the same server, and can be processed
independently, which allows better scaling than SQL databases. Don’t forget,
scaling is one of the primary characteristics in Cloud Computing environments.
The traditional RDBMS may not be a good fit for cloud-scale applications, due
to the strict and upfront schema requirements.
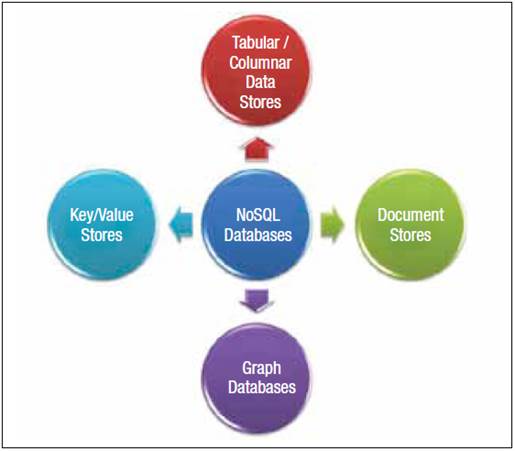
Figure
1: NoSQL databases
Open source NoSQL databases
The NoSQL movement can be defined by a
simple principle: To use the solution that best fits the problem and suits the
objectives. Use a key-value-pair database if the data structure is more
appropriately accessed through this. And if you have connected data such as
social networking or financial transaction graphs, then graph databases are
appropriate.
Many cloud applications demand
availability, speed, and fault tolerance over consistency, and hence have
expanded beyond RDBMS technologies, resulting in the growth of NoSQL databases.
Tabular/ columnar data stores
Tabular/ columnar data stores look similar
to tabular databases. Their primary data retrieval model uses column filters by
leveraging hand-coded map-reduce algorithms.
HBase
HBase is based on Google BigTable and is
column-oriented, open source, and distributed. It uses the Hadoop
infrastructure (Zookeeper as a lock service and NameNode, the HDFS file system)
and hence supports fault tolerance and scalability inherently, and adds random
read-write capability. HBase tables are distributed as regions, and regions are
automatically split and redistributed as data grows. It supports linear and
modular scaling, adding RegionServers that can be hosted on the public cloud.
Regions are vertically divided by column families into stores, which are stored
as files on HDFS. Potential use cases and features include:
§
Reads, supported by a single-write master
§
Ordered partitions that support efficient row
scans
§
Range-based scans
§
Batch analysis
§
Large caches
HBase does not have many features such as
triggers, secondary indexes, etc.
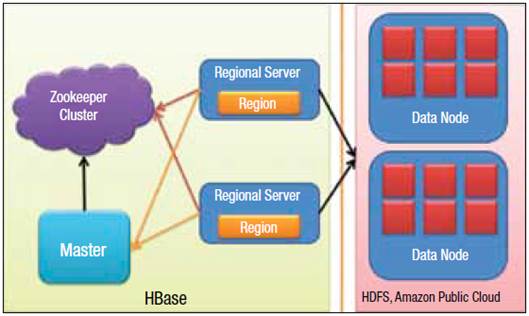
Figure
2: HBase cluster architecture
Hypertable
Hypertable is an open source database
inspired by publications on the design of BigTable. It runs on top of a
distributed file system such as the Apache Hadoop DFS, GlusterFS, or the Kosmos
File System (KFS). It is written almost entirely in C++, for performance. Its
features are:
§
Scalability: It is based on a design developed
by Google to meet scalability requirements.
§
Performance: It offers a responsive user
experience with low request latency.
§
Supports a wide range of applications: Data is
sorted by a primary key
§
Cost saving: It has a high capacity on a tiny
proportion of the hardware.
§
Clean semantics: It has a consistent database.
Figure 3: Hyperspace is a highly available
lock manager and provides a file system for storing small amounts of metadata.
The master handles all Meta operations such as creating and deleting tables;
range servers are responsible for managing ranges of table data, handling all
reading and writing of data; DFS broker provides normalized file system
interface and translates normalized file system requires into native file
system requests and vice-versa; distributed File System
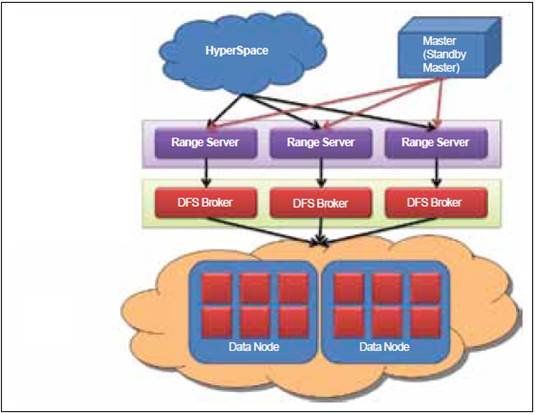
Figure
3: Hypertable model
Document stores
The main concept of a document store is the
document. Document-oriented databases are designed to store, retrieve, and
manage document-oriented structures (like XML files – XML data sources leverage
XQuery), or semi-structured data (like text files – text documents are indexed
and facilitate keyword search-like retrieval). Each document-oriented database
encapsulates and encodes data in some standard format or encodings such as XML,
YAML, or JSON as well as binary forms such as BSON, PDF, and Microsoft Office
documents.